Annotations are a modern concept that are generally used in order to further describe resources or associations between them. The supported information forms a metadata background about the given resource. In general, these resources are simple comments or tags about web pages or textual documents. The Web Annnotation Data Model specification defines a structured model and ways that enable users to construct and share those annotations between different hardware and software platforms.
The MICO Project (Media in Context) makes use of the concept of annotations in another context, as the project deals with the enrichment of multimedia items. The interplay of the media items and their enriched multimedia background promise to broaden the semantic applicability of the items.
The result is this specification, which suggests a metadata model that is an adaption of the Web Annotation Data Model specification. It shows ways of modeling the metadata background of given multimedia items like audio, video, text, etc.
This specification is the second iteration of the metadata model for the MICO project. This is work in progress, so no section should be considered final. The absence of content does not imply that such a content is out of scope or may not appear in the future.
The produced model adapts core features from the Open Annotations Community Group's and Web Annotation Working Group's outcomes. Details and differences can be seen at respective instances in the specification, which enlists both the model items of the OA/WADM specification and the adapted MICO item.
Introduction
Whereas the former Web mostly consisted of information represented in textual documents, nowadays the Web includes a huge number of multimedia documents like videos, photos, and audio. This enormous increase in volume in the private, and above all in the industry sector, makes it more and more difficult to find relevant information. Besides the pure management of multimedia documents, finding hidden semantics and interconnections of heterogeneous cross-media content is a crucial task and stays mostly untouched.
To overcome this tendency, the MICO Project defines a cross-media analysis platform, whose functionality ranges from extracting relevant features from media objects over to representing and publishing extraction results to integrated querying of aggregated findings. This specification defines the ontology that persisted data has to follow, forming the underlying foundation of the platform. The proposed model is based on existing ontologies, adapted and extended to the cross-media environment of the project. Its structure of the core information holder, the annotation, is adapted from the model proposed by the WAWG Group, while our model focuses on the recombination of the annotations, in order to generate a combined metadata analysis background of a given multimedia asset.
This specification forms the core architecture for the MICO model use case. Another specification, called MICO Metadata Model Terms (link to documentation), outlines specially for various use cases implemented body- and target structures, that make use the model presented here.
Aims of the Model
The primary aim of the model is to provide the means to represent a given multimedia item with its rich metadata background, consisting of different final and intermediary extraction results of autonomous extractors. A simple tree-like structure enhanced with provenance features and elements allows for easy (re-)use of the whole process result.
Extraction results are represented as an annotation, an entity that combines its semantical content with a refined description of its target. This structure is based on the simple architecture of the Web Annotation Data Group. However, our model only defines the structure to combine various different annotations, while the content of the annotation is extensible, so third parties can make use of the MICO model by integrating their own extractors and extraction results in the MICO environment.
Diagrams and Examples
The examples throughout the document are depicted by a picture, which is then serialized in [[!TURTLE]]. They do not represent specific use cases with real resources, but rather try to depict a certain feature of the specification.
Instances are represented as colored ellipses.
Instances without an URI are illustrated as colored ellipses with double lines.
Classes are depicted as white rectangles.
Literals are presented as white rounded rectangles.
Class instatiation, relationships and properties are represented as straight, black lines.
Example instance identifiers are lowercase and end in a number.
For example, part1 is a specific instance of a Part, whereas mmm:Part is a class.
Example literals follow the requirements for the model and, thus, must not be interpreted as the only possible value.
Changes to Version 1 of the MICO Metadata Model
In this section, the changes of the MICO Metadata Model are enlisted in short. The changes, or more specifically the current implementation is shown the the corresponding section of the following chapter. The most meaningful changes done from version 1 to version 2 are:
Namespace: The namespace abbreviation for the MICO Metadata Model mico was changed to mmm. This change was necessary because of the introduction of new data models in version 2 (e.g. broker vocabulary).
Aggregation of the concept of content part and annotation: Both concepts are combined, using the class mmm:ContentPart (which will be split in two classes soon), which is derived from oa:Annotation. All information of both former concepts is gathered at this level.
mmm:ContentPart will be renamed to mmm:Part, mmm:ContentItem will be renamed to mmm:Item. This is done for reasons of clarity, the content in all of them was confusing.
Location information of annotations that produce file outputs: The location information of a file output, formerly present in the target of the given annotation, is now included at mmm:Resource-level, so the content item or content part itself contains the location information (property mmm:hasLocation). The same thing counts for the format of the file (property mmm:hasFormat). See composition.
Input/Output provenance: In version 1, there were difficulties specifying the input and output of an annotation in an extensive and descriptive way. Model v2 introduces new ways of declaring the input in two different semantic levels, while the output is moved to another instance, as described in the point above. The input can now refer to its actual input data, and the multimedia file that it is extracted from and reliant on. See provenance.
Less significant changes are:
Introduction of mmm:Resource: A mmm:Resource is introduced as a class that subsumes all available content related MICO items and parts. This was used in order to enhance the OWL definitions of the composition. See composition.
Introduction of inherited WADM classes, relationships and, properties: The MMM adopts many classes, relationships, and properties with the same name and same function, but restricts or expands its multiplicity for MICO purposes, e.g. oa:hasTarget becomes mmm:hasTarget.
Superclass mmm:Body: A superclass mmm:Body is used for all the bodies implemented in the MICO context. All implementations are using the namespace Mico Metadata Model Terms (mmmterms).
Provenance extractor information: As extractors will have different configurations and modi, extractor information has to be implemented in a more extensible way. The introduction of mmm:ExportConfiguration allows to define the confugurations of extractors, which the are linked to from the annotations. See provenance.
Basic Annotation Design
This section will describe the basic annotation design implemented in the MICO platform. The designed ontology incorporates other existing ontologies. Adaptions and extensions will be explained at the specific features of the model.
The Web Annotation Working Group (see WAWG Group) defines the term "web annotation" as a piece of further description (e.g. marginalia or highlight) for a digital resource like a comment or tag on a single web page or image, or a blog post about a news article. Annotations are used to convey information about a resource or associations between resources. In MICO, the interpretation of the annotation-concept is broadened in order to make it applicable to a cross-media context. With a new facet of interactivity, the annotation now describes final and intermediary results of MICO workflow processes. Consequently, an annotation (and/or the accumulation of annotations) can further specify the initially inserted multimedia asset.
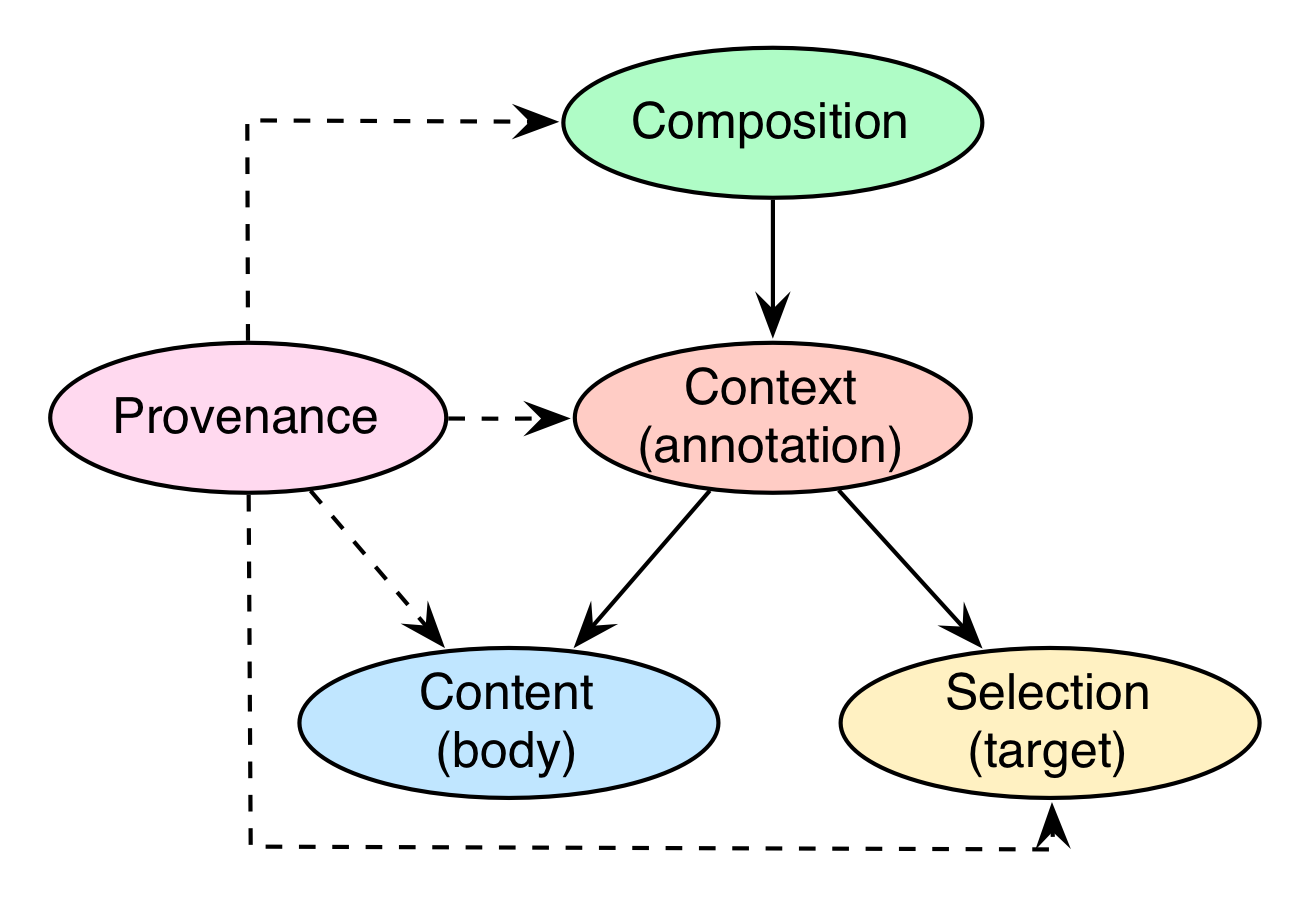
In order to implement this kind of structure, we adopted the three base concepts of the WADM, namely annotation (module context), target (module selection), and body (module content), and extend the structure by a composition module (see composition), which contains ways of describing the interplay of the annotations and the composition of items and their (intermediary) results. Provenance will be provided at various levels of the item and parts (module provenance) and will cover information like who created the given part and when as well as input and output information. shows the modules and their points of contact.
Module structure of the MMM
The Composition
The composition module represents the key MICO modification to the WADM specification. It enables the semantic combination of various annotations (from here also called parts) to represent the full analysed metadata background of one given multimedia asset. As the parts are the results of different extractor processes, the extraction provenance chain can be retraced. From low- to high level features that are attached to the top level item, its interplay of metadata allows for even more feature recombination to create a richer metadata background.
The core structure for every ingested multimedia asset is tree-like (as there are cross and backward oriented edges). At the top level is a mmm:Item, representing the initially ingested multimedia item. This asset is described by a mmm:Asset, which is connected to the item via the relationship mmm:hasAsset. There, the location (property mmm:hasLocation) and the format (property mmm:hasFormat) of the multimedia asset is persisted. Also attached to the item is the metadata information, enclosed as single or multiple mmm:Part nodes (see module context). A mmm:Part will form the information holder and it is connected via the relationship mmm:hasPart to the item. A class mmm:Resource subsumes all items and parts in a disjoint union.
Vocabulary
Item
Type
Description
mmm:Resource
Class
Class that disjointly subsumes the classes mmm:Item and mmm:Part. This class is not used directly, only its subclasses are.
mmm:Item
Class
Class to represent a multimedia asset in context of its full metadata background, generated by applied extractors. MAY have zero or more mmm:hasPart relations associated. MUST have a relationship mmm:hasAsset associated.
oa:Annotation
Class
The WADM class for Annotations. The oa:Annotation class MUST be associated with an Annotation.
mmm:Part
Class
Subclass of oa:Annotation. The class for a part. Parts are results of analysis components with different media types that are directly related to the same mmm:Item. The mmm:Part class MUST be associated with a part. MAY have any number of relationships mmm:hasAsset associated.
mmm:hasPart
Relationship
Links from a mmm:Item to a mmm:Part, indicating that the result of the part is extracted from the given multimedia asset, which consequently features that the part is a component of the asset's metadata background.
mmm:Asset
Class
Class to represent a multimedia asset in the MICO workflow. MUST have a mmm:hasLocation and mmm:hasFormat property associated.
mmm:hasAsset
Relationship
Relationship between a mmm:Resource and its corresponding multimedia asset.
mmm:hasLocation
Property
Refers to the file location of the associated asset of a mmm:Resource. There MUST be exactly one mmm:hasLocation associated with a given mmm:Asset.
mmm:hasFormat
Property
The file format, physical medium, or dimensions of the resource. There MUST be exactly one mmm:hasFormat associated with one given asset.
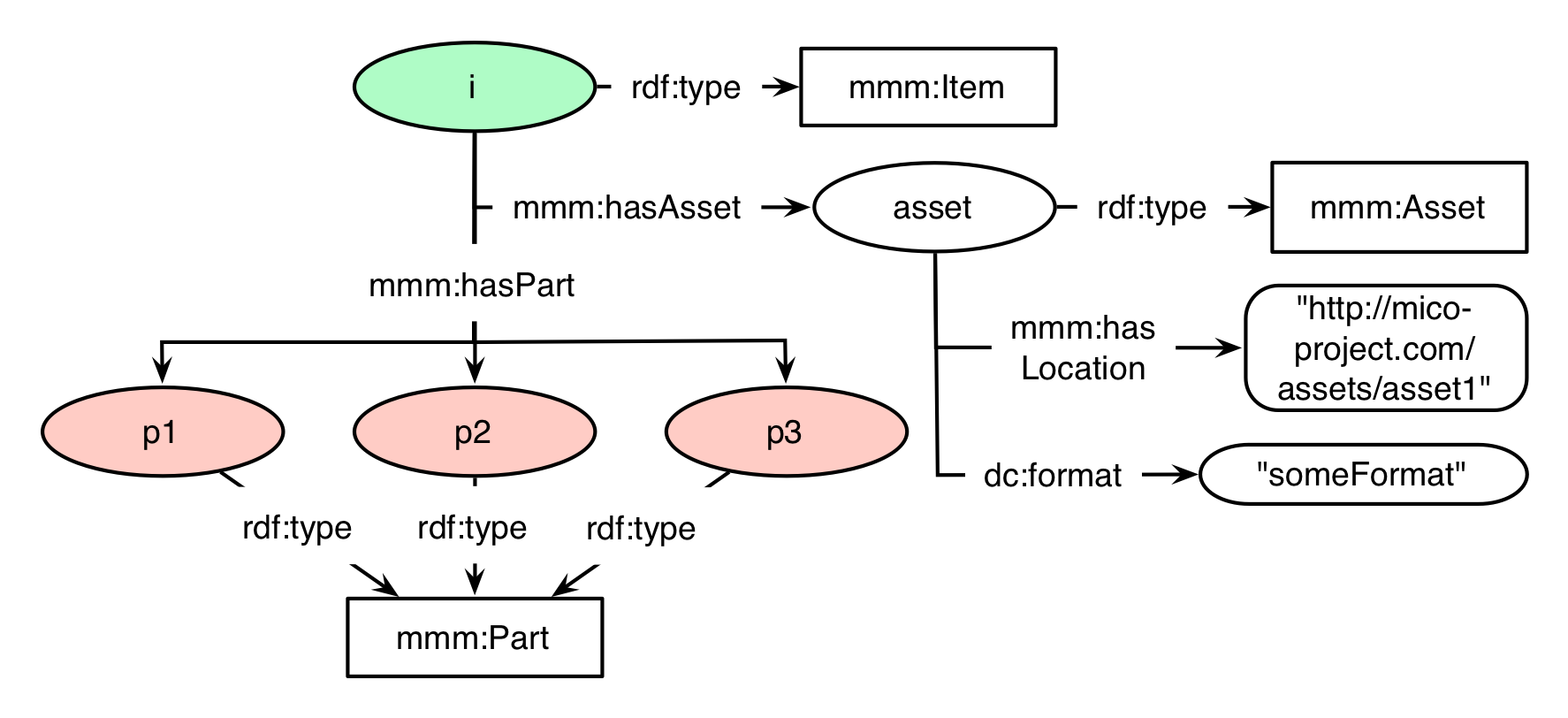
shows an exemplary structure of a mmm:Item. The node with the name "i" is the top-level mmm:Item, with an mmm:Asset, which corresponds to its file at location "http://mico-project.com/assets/asset1" and the format "someFormat". Three parts, namely "p1", "p2", and "p3", are attached as mmm:Part via the relationship mmm:hasPart.
Item structure
Serialization
<urn:i> a mmm:Item ;
mmm:hasFormat "someFormat" ;
mmm:hasLocation "http://mico-project.com/assets/asset1" ;
mmm:hasPart <urn:p1> ;
mmm:hasPart <urn:p2> ;
mmm:hasPart <urn:p3> ;
mmm:hasAsset <asset>.
<asset> a mmm:Asset ;
mmm:hasLocation "http://mico-project.com/assets/asset1" ;
mmm:hasFormat "someFormat".
<urn:p1> a mmm:Part .
<urn:p2> a mmm:Part .
<urn:p3> a mmm:Part .
The Context / The Content Part
In the WADM, the oa:Annotation class is used as the instance that connects the essential parts of a given annotation: the body contains the actual information of the annotation, while the target states the "aim of the annotation", or more specifically, it describes the asset that the annotation is about. The MMM does apply the same structure by introducing the mmm:Part as a subclass of oa:Annotation as context instance. It will also contain various provenance features (see section on provenance). Every part will form a section of the full extracted metadata background of a given mmm:Item.
A part is a web resource and SHOULD have an HTTP URI. All parts MUST be instances of the class mmm:Part.
Typically a part has a single body, which contains the information of an intermediary or final result of a given workflow chain (see section on the content). The target of the part, the "thing" that the given piece of information is about, is referenced by the selection component of the part (see section selection).
The body (or content module) and the target (or selection module) are referenced via the relationships mmm:hasBody and mmm:hasTarget respectively. New sub-relationships of oa:hasBody and oa:hasTarget have been created in order to implement the necessary multiplicity.
Vocabulary
Item
Type
Description
oa:hasBody
Relationship
The relationship between an annotation and the body of the annotation. There SHOULD be 1 or more oa:hasBody relationships associated with an annotation but there MAY be 0.
oa:hasTarget
Relationship
The relationship between an annotation and the target of the annotation. There MUST be 1 or more oa:hasTarget relationships associated with an annotation.
mmm:hasBody
Relationship
Subclass of oa:hasBody. The relationship between a part and its body. There MUST be exactly one body associated with every mmm:Part.
mmm:hasTarget
Relationship
Subclass of oa:hasTarget. The relationship between a part and its target(s). There MUST be at least one target associated with a mmm:Part, but there MAY be more.
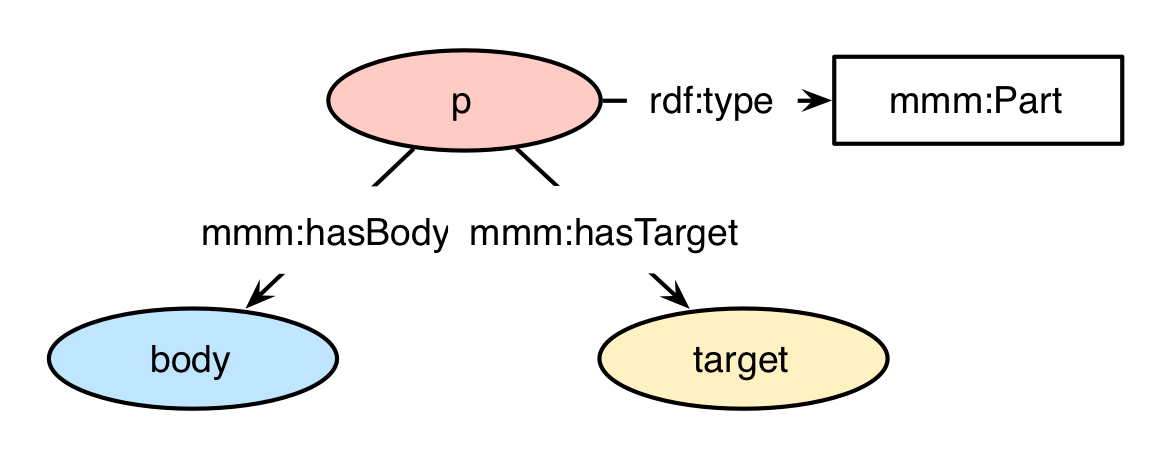
shows the basic structure of a mmm:Part. It is adopted from the basic structure of an annotation in the WADM. The content part "cp" links to its body and target nodes via the relationships mmm:hasBody and mmm:hasTarget respectively. The content for the body and target nodes will be explained in the corresponding sections.
Basic part structure
Serialization
<urn:p> a mmm:Part ;
mmm:hasBody <urn:body> ;
mmm:hasTarget <urn:target> .
The Content / The Body
The body contains the actual content of the annotation. This is the fraction of the mmm:Part that contains the actual information of the given extraction result. In the MICO context, a part MUST always have exactly one body node, connected via the relationship mmm:hasBody. A super class mmm:Body exists for the bodies. Every implemented body MUST be a subclass of this class.
An extensible list of the bodies and corresponding mmm:Part examples that evolved during the MICO use case can be seen in the mmmterms documentation.
Vocabulary
Item
Type
Description
mmm:Body
Class
Superclass for all implemented bodies. The body describes and classifies the results or outcomes of extractors. This class is not directly used for parts, but its subclasses are.
The Selection / The Target
The selection module includes the vocabulary to specify the "target" of the annotation. So given the body as the actual content, the selection section specifies the item that the annotation is about. For example, a simple text annotation can target a video, a certain section of a picture, or a text document. The WAWG Group states that "the body is somehow about the target", so the body further describes the "thing" that is referenced by the mmm:Part.
The selection (or target) side of a mmm:Part is implemented by the utilisation of a mmm:SpecificResource, which is a subclass of oa:SpecificResource. A specific resource is used, when the target needs further specification. As the model addresses different kinds of targets, the structure of the specific resource is adapted. The specific resource links to the actual target of the part (which is a mmm:Resource) with the relationship mmm:hasSource. The specific resource instance node itself is connected to its mmm:Part node via mmm:hasTarget. There MUST be at least one target specified for a part, but there MAY be more. An example for this may be an NER (Named Entity Recognition) entity, that is connected to a text part as well as a fragment of an audio file, so in terms, two specific resources are needed.
As annotations should not only be able to target whole multimedia assets, it is necessary to target subparts of the given asset. For this purpose, the specific resource can be enhanced. This is done by adding a oa:Selector (see section selectors for available implementations) via the relationship oa:hasSelector connected to the specific resource.
Vocabulary
Item
Type
Description
oa:SpecificResource
Class
The class for specific resources. The oa:SpecificResource class SHOULD be associated with a specific resource to be clear as to its role as a more specific region or state of another resource.
mmm:SpecificResource
Class
Subclass of oa:SpecificResource. A specific resource describes what the body is about and can be extended with more precise selections to only refer to a temporal or spatial fragment of a multimedia asset. There MUST be at least one specific resource associated with a mmm:Part, but there MAY be more. MUST have exactly one source via relationship mmm:hasSource, MAY have 0 or 1 selector assigned via the relationship mmm:hasSelector.
oa:hasSource
Relationship
The relationship between a specific resource and the resource that it is a more specific representation of. There MUST be exactly 1 oa:hasSource relationship associated with a Specific Resource.
mmm:hasSource
Relationship
Subclass of oa:hasSource. There MUST be exactly ONE mmm:hasSource associated with a mmm:SpecificResource. Links to a mmm:Resource.
oa:hasSelector
Relationship
The relationship between a specific resource and a selector. There MUST be exactly 0 or 1 oa:hasSelector relationship associated with a specific resource.
mmm:hasSelector
Relationship
Subclass of oa:hasSelector. The relationship between a MICO specific resource and its potential selector. The MUST be exaclty 0 or 1 mmm:hasSelector associated with a MICO specific resource.
oa:Selector
Class
The super class for individual selectors. This class is not used directly in annotations, only its subclasses are.
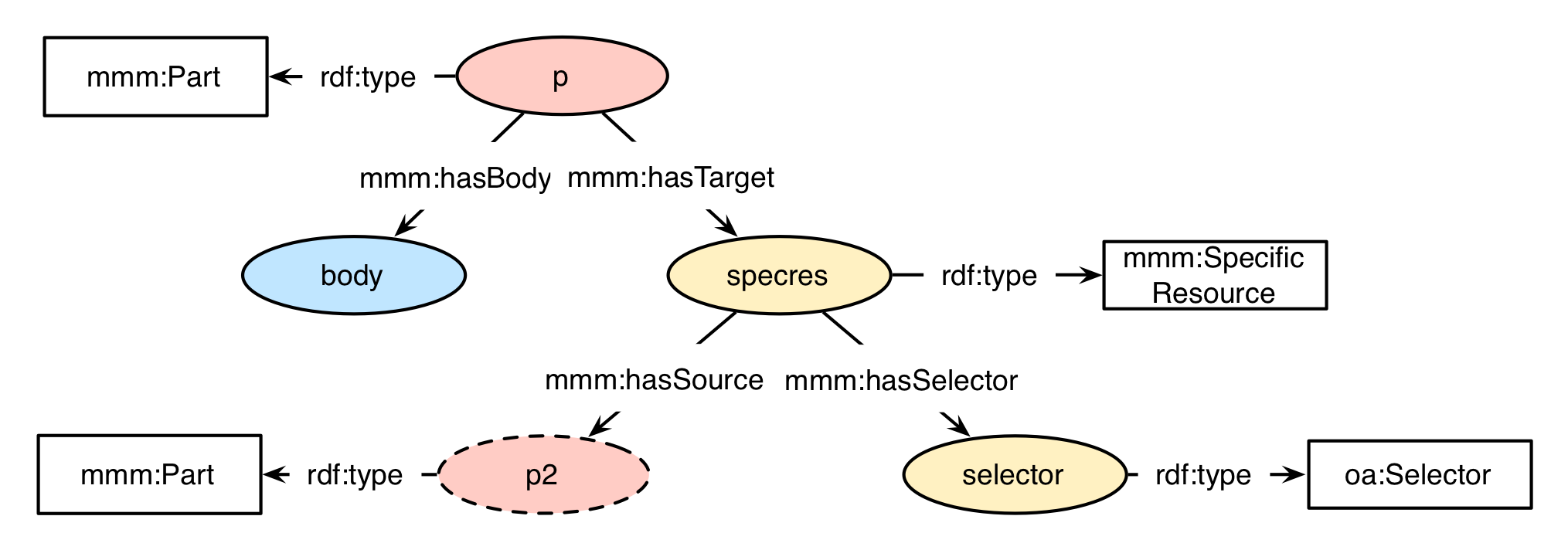
shows an exemplary part with selection information. This is done by adding the specific resource "specres", which links to the input part "p2" via the relationship mmm:hasSource. The supported selector "selector" can be enhanced with the subpart information in order to only select a subpart of the input "p2" (see section for selector implementations).
Selection example
Serialization
<urn:p> a mmm:Part ;
mmm:hasBody <urn:body> ;
mmm:hasTarget <urn:specres> .
<urn:specres> a mmm:SpecificResource ;
mmm:hasSource <urn:p2> ;
mmm:hasSelector <urn:selector> .
<urn:p2> a mmm:Part .
<urn:selector> a oa:Selector .
Selectors
The selectors defined by the WADM are divided into three bigger classes: fragment selectors, range selectors, and area selectors. Every selector is subclass of oa:Selector, and it is used to further specify which subpart of a given multimedia asset is to be selected for a mmm:Part. The selector is connected to the mmm:SpecificResource of the given part via mmm:hasSelector.
Fragment Selectors
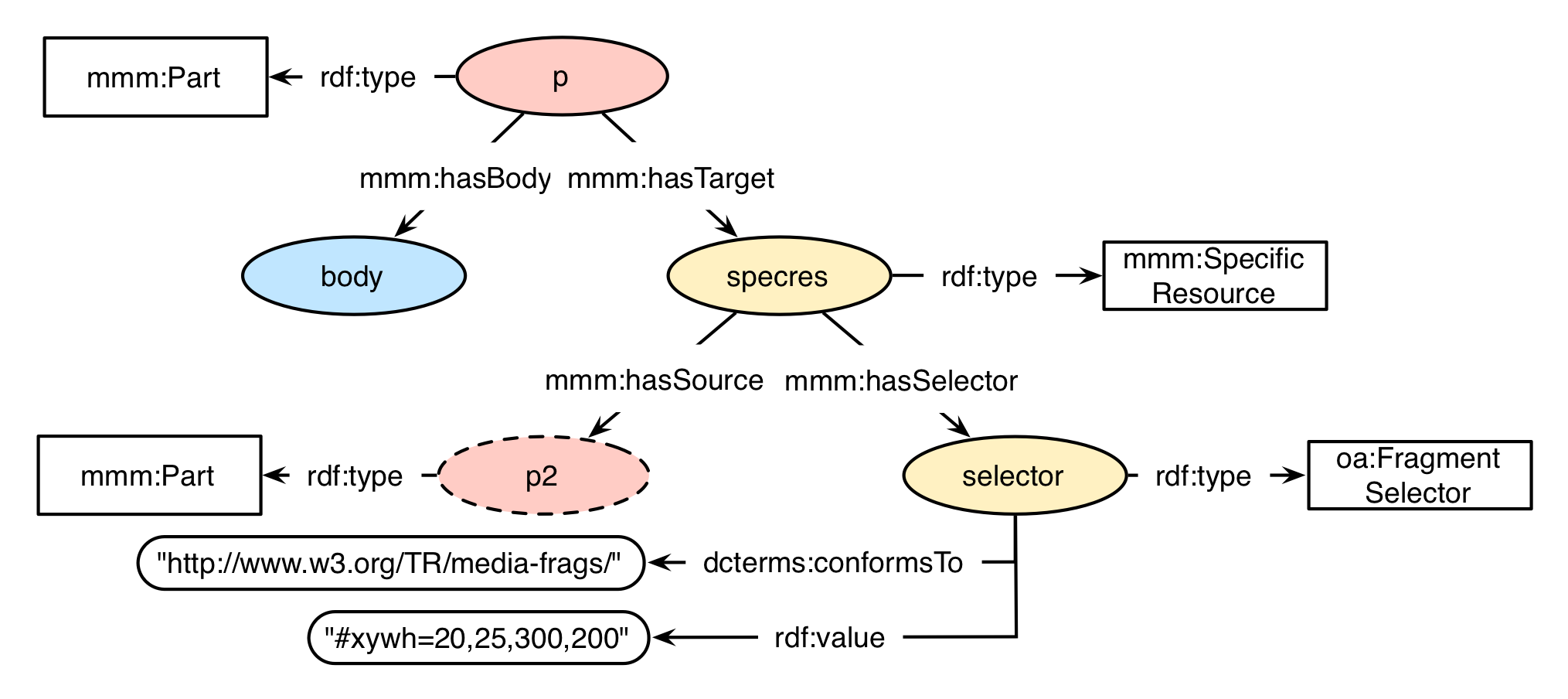
Fragment selectors refer to the fragment of a URI, which is in many cases used in order to specify a certain part of a given resource. The URI fragment specifications supported by the WADM are XHTML, PDF, text/plain, XML, RDF, the W3C Media Fragments, and SVG. The corresponding link to the specification MUST be supported via dcterms:conformsTo at the selector node. The actual fragment MUST be associated via the property rdf:value. The given selector node has to be typed as oa:FragmentSelector.
The WADM allows the fragment to be appended to the URI directly, but it is RECOMMENDED to support it at selector level. Consuming clients should be aware of both possibilities.
Vocabulary
Item
Type
Description
oa:FragmentSelector
Class
Subclass of oa:Selector. A resource which describes the segment of interest in a representation through the use of the fragment identifier component of a URI.
dcterms:conformsTo
Property
The fragment selector SHOULD have a dcterms:conformsTo property with the object being the specification that defines the syntax of the fragment.
rdf:value
Property
rdf:value is an instance of rdf:Property that may be used in describing structured values.
shows an example of a selector conform to the W3C Media Fragments. This is done by refering to the specification via dcterms:conformsTo with the value "http://www.w3.org/TR/media-frags/" and supporting the specific fragment with rdf:value. In this case, the fragment is set to "#xywh=20,25,300,200", which corresponds to a rectangular subpart of the given media asset (for a media fragment a picture or video, contained in p2) starting at the pixel with x-coordinate "20" and y-coordinate "25", being directed to the bottom right with a width and height of "300" and "200" pixels respectively.
W3C Media Fragments conform selector example
Serialization
<urn:p> a mmm:Part ;
mmm:hasBody <urn:body> ;
mmm:hasTarget <urn:specres> .
<urn:specres> a mmm:SpecificResource ;
mmm:hasSource <urn:p2> ;
mmm:hasSelector <urn:selector> .
<urn:p2> a mmm:Part .
<urn:selector> a oa:FragmentSelector ;
dcterms:conformsTo "http://www.w3.org/TR/media-frags/" ;
rdf:value "#xywh=20,25,300,200" .
Range Selectors
Range selectors are used when a subpart of linear data has to be selected. This is done by supporting a start and end marker. The WADM provides three different selectors for this class.
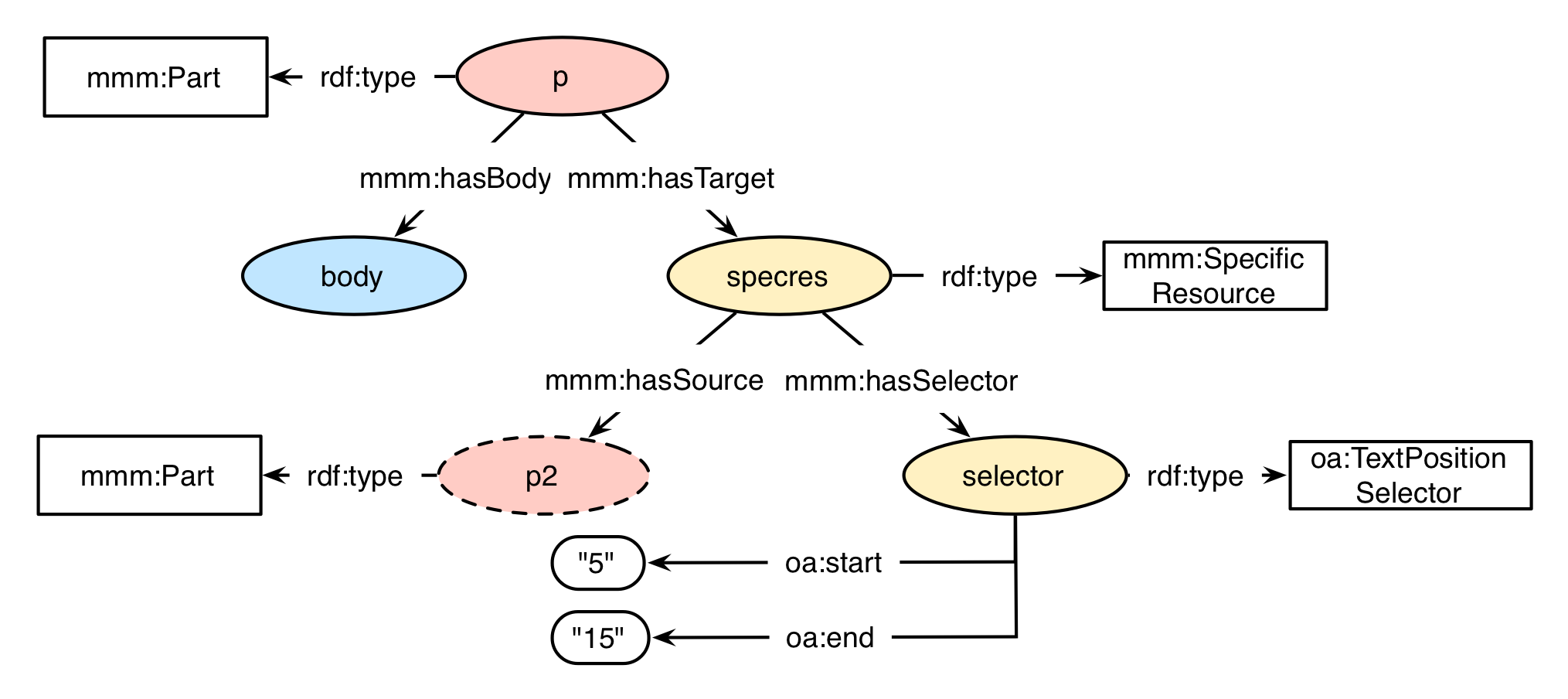
A oa:TextPositionSelector extracts a text excerpt (specified by a start and end character) from an ordered list of characters. A number supported for the respective properties oa:start and oa:end (connected to the extractor node) define where the snippet is to be found. The position "0" would be immediately before the first character of the text, "1" before the second character etc. It is RECOMMENDED to normalise the text input before the selection, changes to the text MAY apply to the selection as well. The text excerpt is not copied.
The oa:TextQuoteSelector works similar to the oa:TextPositionSelector, but rather than specifying positions in the text, one can define exact text matches or select an excerpt by defining a prefix and/or suffix. The corresponding properties are oa:exact, oa:prefix, and oa:suffix respectively. It is also RECOMMENDED here to normalise the text, and in contrast to its similar text position selector, the oa:TextQuotationSelector copies the subpart of the text that it selects.
The oa:DataPositionSelector is also very similar to the text position as it also makes use of start (property oa:start) and end (property oa:end) tags to select its snippet, but it works on bytes of a bitstream instead of text.
Vocabulary
Item
Type
Description
oa:TextPositionSelector
Class
Subclass of oa:Selector. The class for a selector which describes a range of text based on its start and end positions.
oa:start
Property
The starting position of the segment of text. The first character in the full text is character position 0, and the character is included within the segment.
oa:end
Property
The end position of the segment of text. The last character is not included within the segment. Each oa:TextPositionSelector MUST have exactly 1 oa:end property.
oa:TextQuoteSelector
Class
Subclass of oa:Selector. The class for a selector that describes a textual segment by means of quoting it, plus passages before or after it.
oa:exact
Property
A copy of the text which is being selected, after normalisation. Each oa:TextQuoteSelector MUST have exactly 1 oa:exact property.
oa:prefix
Property
A snippet of text that occurs immediately before the text which is being selected. Each oa:TextQuoteSelector SHOULD have exactly 1 oa:prefix property, and MUST NOT have more than 1.
oa:suffix
Property
The snippet of text that occurs immediately after the text which is being selected. Each oa:TextQuoteSelector SHOULD have exactly 1 oa:suffix property, and MUST NOT have more than 1.
oa:DataPositionSelector
Class
Subclass of oa:Selector. The class for a selector which describes a range of data based on its start and end positions within the byte stream.
shows an exemplary use of a oa:TextPositionSelector. From the corresponding text file (referenced via content part "p2") the text excerpt starting with character at position 5 to 15 would be selected by supporting the properties oa:start and oa:end respectively.
TextPositionSelector example
Serialization
<urn:p> a mmm:Part ;
mmm:hasBody <urn:body> ;
mmm:hasTarget <urn:specres> .
<urn:specres> a mmm:SpecificResource ;
mmm:hasSource <urn:p2> ;
mmm:hasSelector <urn:selector> .
<urn:p2> a mmm:Part .
<urn:selector> a oa:TextPositionSelector ;
oa:start "5" ;
oa:end "15" .
Area Selectors
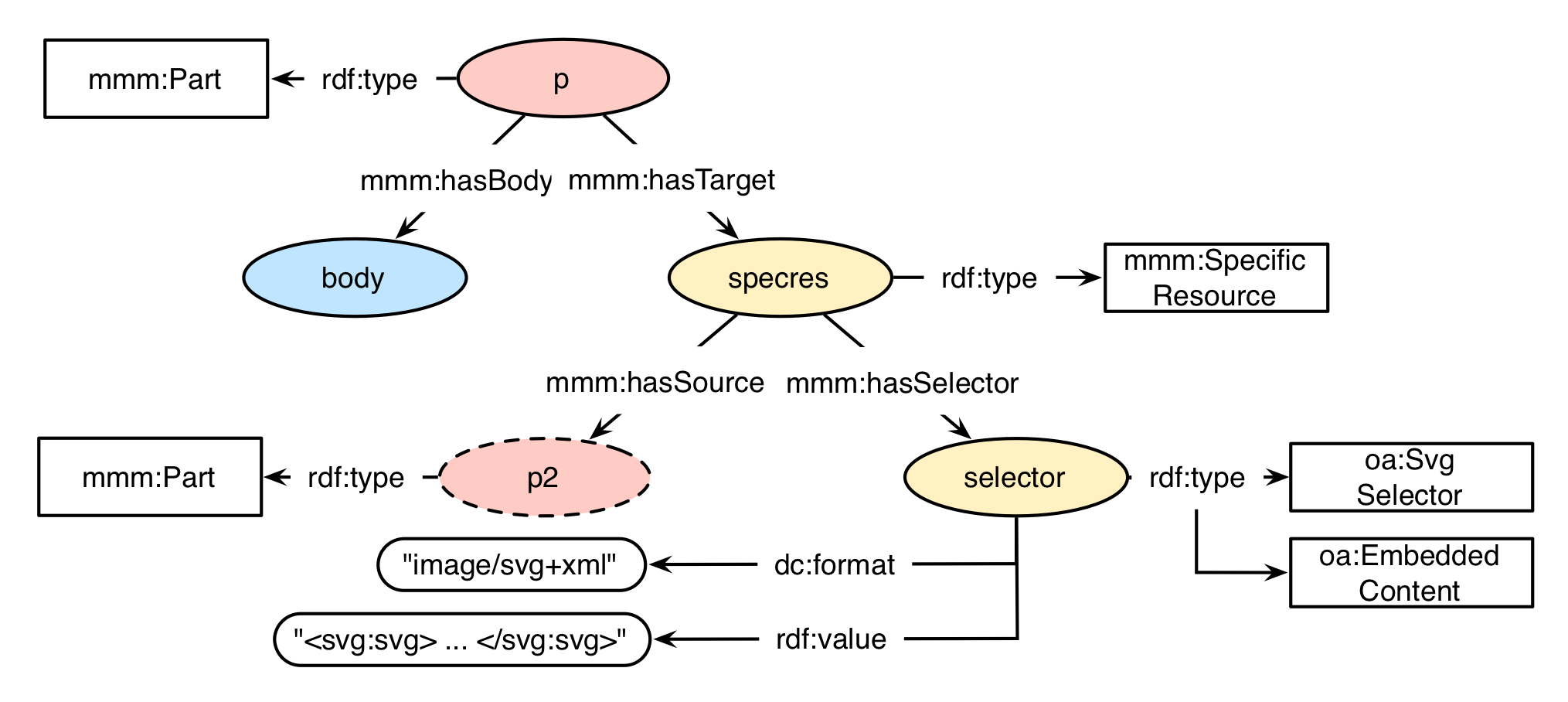
Area selectors allow the user not only to select rectangular areas of a given media asset, but more complex shapes, like polygons, circles, and elipses. The only current area selector is the oa:SvgSelector, which allows for the utilisation of a Scalable Vector Graphics vector to specify the subpart of the given multimedia asset. For an annotation, it is RECOMMENDED to only contain one shape in the vector. The dimensions of the SVG vector MUST be relative to the source resource. It is NOT RECOMMENDED to include style, javascript, animation, text, or other non-shape information withing the SVG element.
Vocabulary
Item
Type
Description
oa:SvgSelector
Class
Subclass of oa:Selector. The class for a selector which defines a shape using the SVG standard.
There are two possibilities of including the SVG vector into a mmm:Part construct. The SVG document MAY be a seperate resource, or embedded within the annotation's serialisation. shows an example of a seperate resource. In order to mark the embedded content in particular, a second type oa:EmbeddedResource is added to the selector node.
SvgSelector example
Serialization
<urn:p> a mmm:Part ;
mmm:hasBody <urn:body> ;
mmm:hasTarget <urn:specres> .
<urn:specres> a mmm:SpecificResource ;
mmm:hasSource <urn:p2> ;
mmm:hasSelector <urn:selector> .
<urn:p2> a mmm:Part .
<urn:selector> a oa:SvgSelector, oa:EmbeddedResource ;
mmm:hasFormat "image/svg+xml" ;
rdf:value "<svg:svg> ... </svg:svg>" .
Provenance
Provenance information is important on several occasions during a MICO workflow process. It is crucial to document that information, as it forms the documented history and origin of data. As a result, extraction workflows can be traced back, confidence and trust values can be assigned, and the simple question of "who did what and at which time?" can be answered.
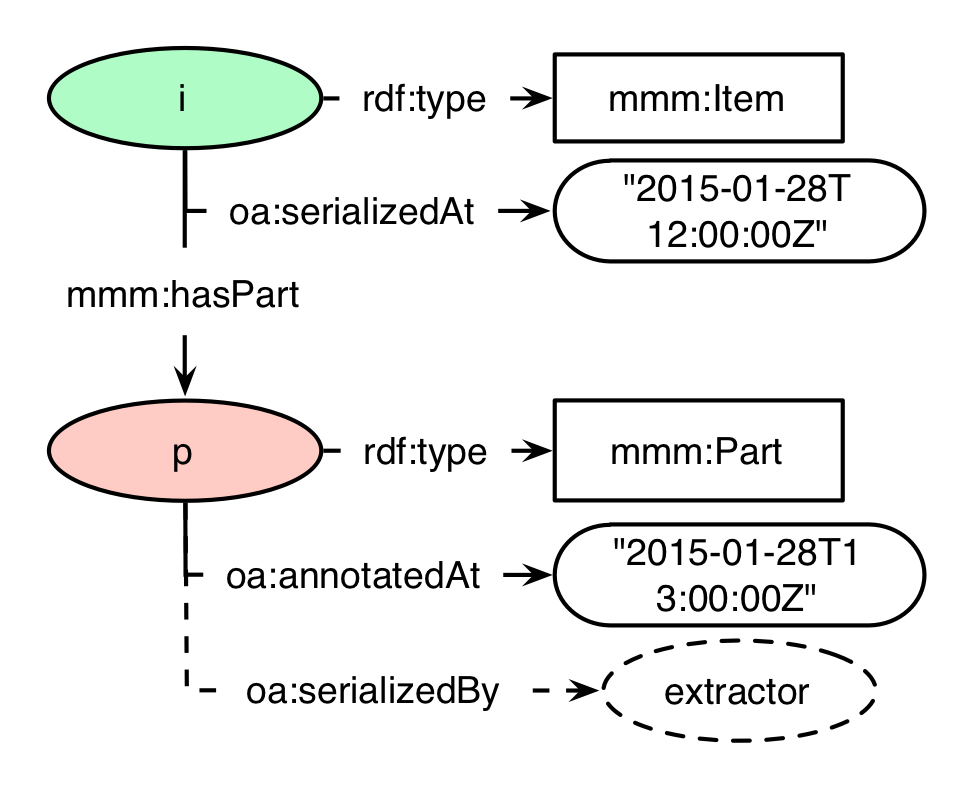
One big part of the provenance information of the MICO Metadata Model are the timestamps and the allocation of who did create a given mmm:Part. This information will be added at two spots of the metadata construct: the mmm:Item and the mmm:Part. Items will always be initially created by the MICO platform itself, so there will not be an agent (the entity that is responsible for creation of the item) stored there. The timestamp however will be associated via the property oa:serializedAt. The timestamps MUST be expressed in the xsd:dateTime format, and they SHOULD have a timezone specified (e.g. "2015-01-28T12:00:00Z"). For a part, the timestamp will be stored at the property oa:annotatedAt. Additionally, it is important to track who was the creator of the given part. In the MICO use case, this will always be an extractor of some kind. The extractor will be linked to the part node via the relationship oa:serializedBy.
Vocabulary
Item
Type
Description
oa:serializedAt
Property
The time at which the MICO platform serialized the corresponding content item, or a given part has been created at extractor side. There MUST be exactly one oa:serializedAt property associated for every content item, and should be associated for every part. The datetime MUST be expressed in the xsd:dateTime format, and SHOULD have a timezone specified.
oa:serializedBy
Relationship
Subproperty of prov:wasAttributedTo. The object of the relationship is a resource that identifies the agent responsible for creating the content part. This MUST always be an extractor/software agent in the MICO context. There MUST be exactly 1 oa:serializedBy relationship per content part. In general, this edge is directed towards an mmm:Extractor node.
oa:annotatedAt
Property
The time at which the content part was received at the MICO platform instance and then persisted at the respective triplestore. There MUST be exactly 1 oa:annotatedAt property per content part. The datetime MUST be expressed in the xsd:dateTime format, and SHOULD have a timezone specified.
mmm:hasInput
Relationship
Refers to the mmm:Resource that contains the information needed to generate the corresponding new part. A mmm:Part MUST have at least one mmm:hasInput relation associated, but MAY have multiple ones.
shows an example of a mmm:Item "i" and its mmm:Part "p" with its time provenance information. The item has been created at the timestamp "2015-01-28T12:00:00Z", indicated by the property oa:serializedAt. The corresponding part has been created later at "2015-01-28T13:00:00Z", as shown by the property oa:annotatedAt, while its producer is associated via the relationship oa:annotatedBy. As the information for extractors will follow later, there is just a placeholder.
Timestamp provenance example
Serialization
<urn:i> a mmm:Item ;
oa:serializedAt "2015-01-28T12:00:00Z" ;
mmm:hasPart <urn:p> .
<urn:p> a mmm:Part ;
oa:annotatedAt "2015-01-28T13:00:00Z" ;
oa:serializedBy <urn:...> .
Extractors in MICO are represented in an extensive fashion, as extractors will support different modes they can work in. Those modes in turn can have different parameters that will affect the given extractor's output as well as the possible input. A mmm:Part node is associated with a mmm:Extractor over the relationship oa:serializedBy, and additionaly with a mmm:Mode of the respective extractor over the mmm:serializedWith relationship. The vocabulary that has been added for the extractor details is as follows:
Vocabulary
Item
Type
Description
mmm:serializedWith
Relationship
The relationship between a mmm:Part node and the mmm:Mode that is responsible for the extraction of the given part. There can only be exactly one mmm:serializedWith relationship associated with a mmm:Part.
mmm:Extractor
Class
Class for an extractor in the MICO universe. An extractor is associated with exactly one mmm:hasName, mmm:hasVersion, and mmm:hasStringId property, and can have multiple mmm:Mode nodes attached via the mmm:hasMode relationship.
mmm:hasName
Property
The (MICO) name of the associated node.
mmm:hasVersion
Property
The (numerical) version of the associated node.
mmm:hasStringId
Property
The (uniquely identifiable) Id of the associated node, represented as String.
mmm:hasMode
Relationship
The relationship between a mmm:Extractor and its 0 to multiple mmm:Mode nodes.
mmm:Mode
Class
The mode of a given extractor. An extractor can have different modes that are distinguished by means of their parameters and IO data. A mode is associated with exactly one mmm:hasConfigSchemaURI, mmm:hasOutputSchemaURI, mmm:hasStringId, and mmm:hasDescription property, and has possibly multiple mmm:Input, mmm:Output, and mmm:Param nodes attached via the relationships mmm:hasInputData, mmm:hasOutputData, and mmm:hasParam respectively.
mmm:hasConfigSchemaURI
Property
The URI where the config schema is to be found.
mmm:hasOutputSchemaURI
Property
The URI where the output schema is to be found.
mmm:hasDescription
Property
The (textual) description of the associated extractor detail.
mmm:hasInputData
Relationship
The relationship between a mmm:Mode and its associated mmm:Input node. One mode can have 0 to multiple mmm:hasInputData relationships associated.
mmm:hasOutputData
Relationship
The relationship between a mmm:Mode and its associated mmm:Output node. One mode can have 0 to multiple mmm:hasOutputData relationships associated.
mmm:hasParam
Relationship
The relationship between a mmm:Mode and its associated mmm:Param node. One mode can have 0 to multiple mmm:hasParam relationships associated.
mmm:IOData
Class
Superclass for the mmm:Input and mmm:Output classes. Every mmm:IOData node has exactly one mmm:hasIndex and mmm:hasCmdLineSwitch property associated. Additionally, it can have 0 to multiple mmm:hasMimeType, mmm:hasSemanticType, and mmm:hasSyntacticType relationships added.
mmm:hasIndex
Property
The (numerical) index for the associated node.
mmm:hasCmdLineSwitch
Property
The command line switch for the associated node.
mmm:hasMimeType
Relationship
The relationship between a mmm:IOData node and a given mmm:MimeType node. There can be 0 to multiple mmm:hasMimeType relationships.
mmm:hasSemanticType
Relationship
The relationship between a mmm:IOData node and a given mmm:SemanticType node. There can be 0 to multiple mmm:hasSemanticDataType relationships.
mmm:hasSyntacticType
Relationship
The relationship between a mmm:IOData node and a given mmm:SyntacticType node. There can be 0 to multiple mmm:hasSyntacticDataType relationships.
mmm:Input
Class
Subclass of mmm:IOData, representing an input requirement of an extractor.
mmm:Output
Class
Subclass of mmm:IOData, representing an output requirement of an extractor.
mmm:MimeType
Class
Class represents a mime type for a given mmm:IOData node. Has a mmm:hasFormatConversionURI and mmm:hasStringId property associated.
mmm:hasFormatConversionURI
Property
The URI that links to a defined format conversion.
mmm:SemanticType
Class
Class represents a semantic type of a given mmm:IOData node. Has exactly one mmm:hasName, mmm:hasDescription, and mmm:hasSemanticTypeURI property associated.
mmm:hasSemanticTypeURI
Property
The URI linking to the given semantic type.
mmm:SyntacticType
Class
Class represents a syntactic type of a given mmm:IOData node. Has exactly one mmm:hasAnnotationConversionSchemaURI, mmm:hasDescription, and mmm:hasSyntacticTypeURI property associated. Syntactic types can also link to 0 to multiple mime types via the mmm:hasMimeType relationship.
mmm:hasAnnotationConversionSchemaURI
Property
The URI that links to the annotation conversion schema.
mmm:hasSyntacticTypeURI
Property
The URI linking to the syntactic type.
mmm:Param
Class
Class represents a parameter of a given mmm:Mode node. A parameter has exactly one rdf:value and mmm:hasName property associated.
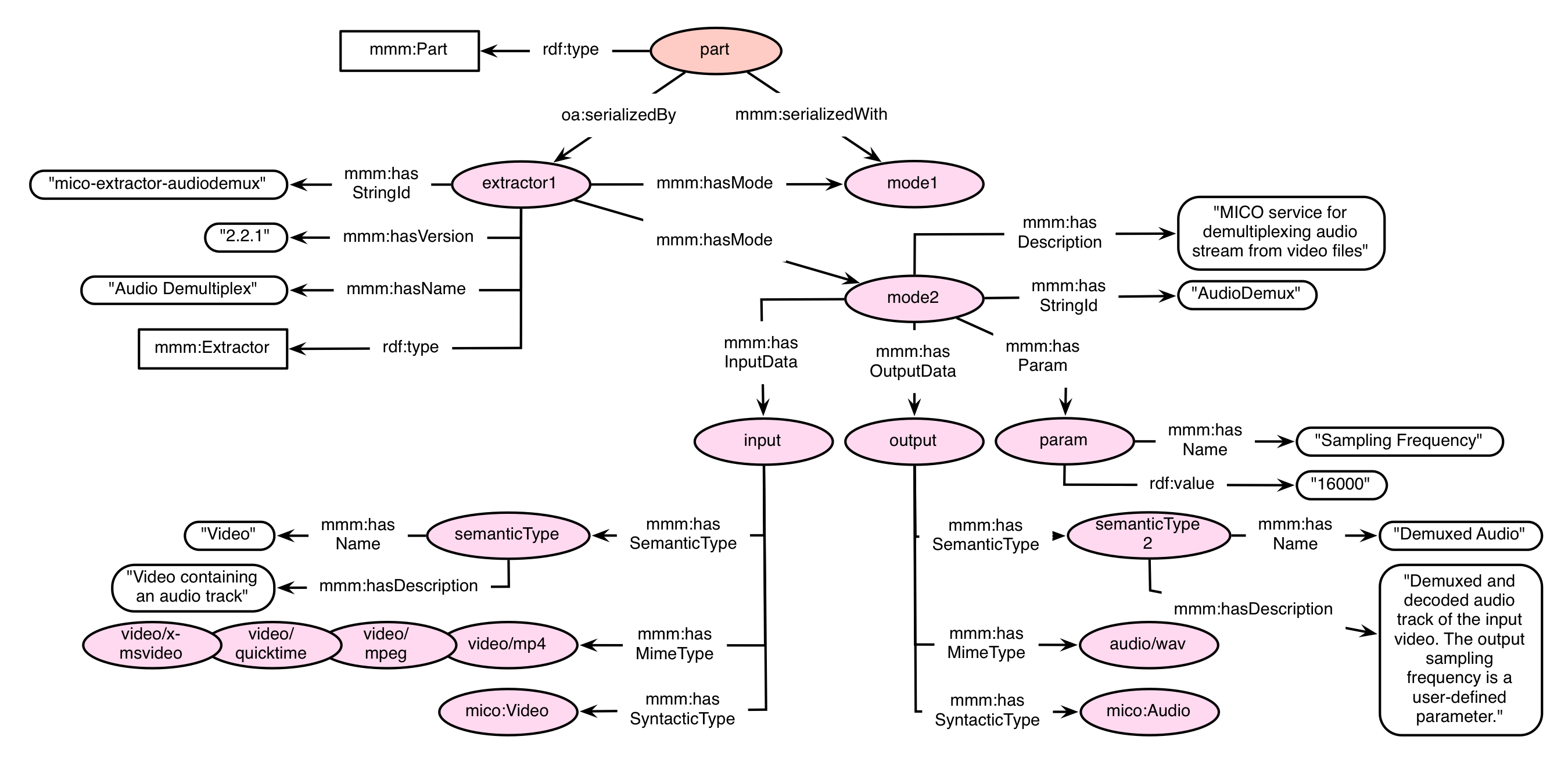
shows an example for the extractor vocabulary, illustrating a MICO audio demux extractor. For the sake of clarity, some nodes were left out (e.g. the rdf:type relationships, as the nodes are named equivalently, and for the example less important properties like conversion URIs). The extractor has two modes, mode1 and mode2, which can have different settings, but in general deal with a similar task. In this example, the sampling frequency for the resulting audio file can differ (depending on what parameter has been defined by the extractor creator). Mode2 is defined to take different video files as input, and produces audio as output, with a defined frequency of 16000.
Exemplary extractor model
<urn:part> a mmm:Part ;
oa:serializedBy <urn:extractor1> ;
mmm:serializedWith <urn:mode1> .
<urn:extractor1> a mmm:Extractor ;
mmm:hasName "Audio Demultiplex" ;
mmm:hasVersion "2.2.1" ;
mmm:hasStringId "mico-extractor-audiodemux" .
<urn:mode1> a mmm:Mode ;
... ;
... .
<urn:mode2> a mmm:Mode ;
mmm:hasStringId "AudioDemux" ;
mmm:hasDescription "MICO service for demultiplexing audio stream from video files."
mmm:hasInputData <urn:input> ;
mmm:hasOutputData <urn:output> ;
mmm:hasParam <urn:param> .
<urn:input> a mmm:Input ;
mmm:hasSemanticType <urn:semanticType> ;
mmm:hasMimeType <urn:video/mp4> ;
mmm:hasMimeType <urn:video/mpeg> ;
mmm:hasMimeType <urn:video/quicktime> ;
mmm:hasMimeType <urn:video/x-msvideo> ;
mmm:hasSyntacticType <urn:mico:Video> .
<urn:semanticType> a mmm:SemanticType ;
mmm:hasName "Video" ;
mmm:hasDescription "Video containing an audio track" .
<urn:output> a mmm:Output ;
mmm:hasSemanticType <urn:semanticType2> ;
mmm:hasMimeType <urn:audio/wav> ;
mmm:hasSyntacticType <urn:mico:Audio> .
<urn:semanticType2> a mmm:SemanticType ;
mmm:hasName "Demuxed Audio" ;
mmm:hasDescription "Demuxed and decoded audio track of the input video. The output sampling frequency is a user-defined parameter." .
<urn:param> a mmm:Param ;
mmm:hasName "Sampling Frequency" ;
rdf:value "16000" .
The next section of crucial provenance information for a mmm:Part is its input. "Input" in the MICO context must be seen twofold. First, there are entities that contain the actual information that is needed to generate the content of the given (new) part. These entities are referenced as the "input of the part". Second, there are the media assets that the given content part is about. This is the "source of the part".
An input of a part is implemented by the relationship mmm:hasInput which points to the mmm:Resource that is used as input. Note that there MUST be at least one mmm:hasInput relationship, but there MAY be multiple, as an extraction step might be in need of multiple inputs. The source of a content part is associated at the mmm:SpecificResource and its relationship mmm:hasSource, as described in section . A part MUST have exactly one mmm:hasSource relationship. Note, that the source and input edges MAY refer to the same entity.
Instances of mmm:Item MUST always have a related multimedia file (as it is the start of a MICO workflow), while a mmm:Part MAY have a multimedia file associated, in case the extraction step creating it also creates a file output. This is implemented by a mmm:Asset, which is connected to the respective item or part via the relationship mmm:hasAsset. The asset node MUST have properties that refer to the location of the file (property mmm:hasLocation) as well as its MIME type or format (property mmm:hasFormat).
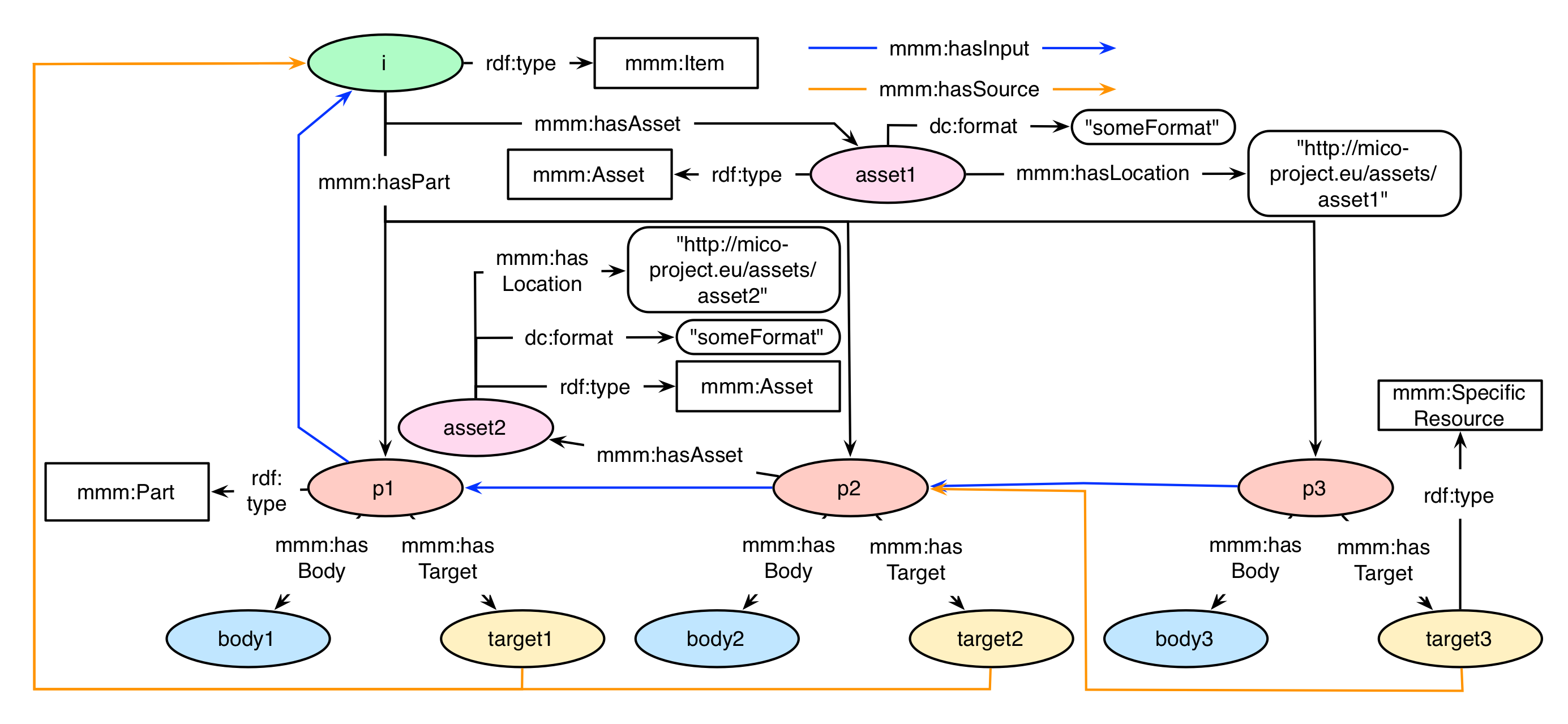
The example in requires a little more explanation, even though the issue of input and output in the MICO context is not complicated:
The workflow behind this example contains the initial ingestion of a media asset "asset1" (at location "http://mico-project.eu/assets/asset1") and three consecutive extractor steps, which will start their extraction once the multimedia asset is ingested at the MICO platform. The first and third extractor (responsible for creating "p1" and "p3" respectively) are "normal" extractors, meaning that they produce metadata information, some intermediary results without a file output. By contrast, extractor two is a process that does output a file, which is indicated by the relationship mmm:hasAsset, refering to its mmm:Asset named "asset2". The location of the created asset is "http://mico-project.eu/assets/asset2". The input and source of every content part is implemented by the relationships mmm:hasInput and mmm:hasSource.
"p1" as the first content part of the workflow chain, refers to the item "i" as its source, so its mmm:hasSource edge (found at the target section "target1") links to the item "i", which in terms stands for the first multimedia asset "asset1". The extractor is some kind of multimedia extractor, so it uses the multimedia file directly as input, indicated by the relationship mmm:hasInput, which is also directed to "i".
The second extractor has another function. It takes the information extracted by the first extractor (and maybe changes it) and outputs a file. The output is indicated via the mmm:hasAsset relationship. As the actual input for part number two is contained in "p1", the mmm:hasInput edge is directed from "p2" to "p1". Its source however is directed to the item "i", because the content part "p2" is about the multimedia asset "asset1", and not the part "p1".
Extractor number three then can take the output of extractor two, as it is some kind of process that needs the multimedia asset "asset2" as input. Because of this, the source of the third part links to "p2" (and not the initial item). As that asset also contains the input needed for the creation of "p3", the mmm:hasInput relationship is also directed towards "p2".
The following table contains all the namespaces and abbreviations of other ontologies that have been (partly) included or used in the design of the MICO Metadata Model. In addition, both the namespaces created for this specification are enlisted.